ODIN: Automated Drift Detection for Video Analytics
Concept drift consists of learning in a non-stationary environment, where the underlying data distribution (i.e., the joint distribution of the input data and labels $P(X,Y)$) evolves over time. It is also referred to as domain adaptation. Drift detection is well studied for sensor data but has made little headway in ML until more recently.
ODIN is a system for automated drift detection for video analytics. While current video analytics systems deliver high performance in object detection, this is usually in narrow circumstances over static data. In practice, the visual data drifts over time because it comes from a dynamic, time-evolving distribution. For instance, a machine learning (ML) model for self-driving vehicles that is not trained on images containing snow does not work well when it encounters them in practice.

How does it work?
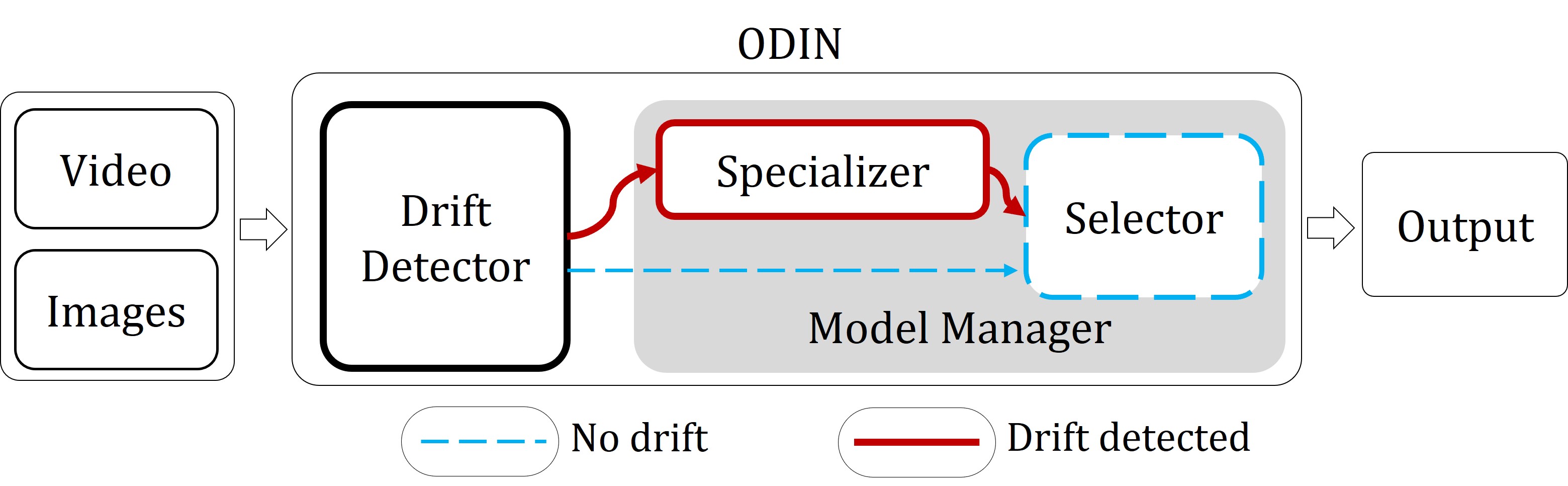
ODIN automatically adapts to changes in distribution with three components:
- Drift Detector identifies changes in the prediction data
- Model Specializer creates specialized models for each cluster
- Model Selector chooses the best fit model for a data point
Take a look at our paper with all the details! Paper at:
Detector
DETECTOR identifies drift in the given data using an unsupervised clustering algorithm tailored for high-dimensional data. It learns the
distribution of clustered density bands in the given data. Intuitively, a high-density region in the latent
space represents a latent concept and changes in this region indicate
changes in the concept itself (i.e., concept drift). A key component
of DETECTOR is the distance metric that it employs for clustering
data points into density bands in an unsupervised manner. We use a learned distance metric with a GAN, by training a GAN to reconstruct
some data and using its latent space 's representation for distance measurement.
Specializer
When DETECTOR identifies drift, ODIN relies on the SPECIALIZER to recover from the detected drift by generating specialized
models for newly detected clusters. SPECIALIZER allows ODIN to
deliver high accuracy across all clusters. In our paper, we demonstrate the importance of specialization by comparing
the accuracy of a non-specialized model trained on the entire dataset
to specialized models optimized for particular clusters.
Selector
Lastly, the SELECTOR is responsible for choosing the appropriate specialized model for a given input to perform inference. When
drift occurs, the SPECIALIZER may take time to collect sufficient
novel data points before constructing a model for the newly detected
cluster. During this phase, SELECTOR dynamically creates an ensemble of specialized models from nearby clusters for inference.
This allows ODIN to perform well during the early phases of drift.
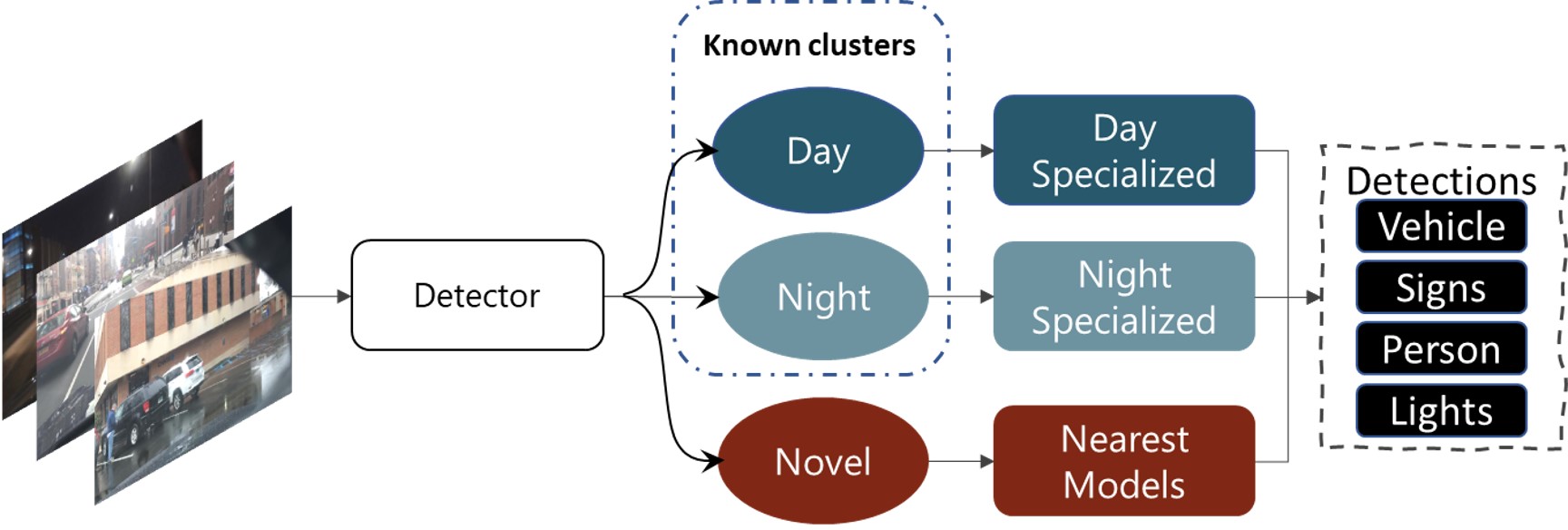
All this comes together in ODIN's dataflow, shown below with respect to the BDD100K dataset of vehicle dashcam footage across multiple weathers, times-of-day, and locations.
Given
an image, DETECTOR performs dimensionality reduction to get
its lower-dimensional manifold. It uses this manifold to map it to
existing clusters from previously seen data. If the input belongs
to an existing cluster, SELECTOR picks the associated model for
inference (e.g., identifying objects in the given BDD image). If
that is not the case, then it picks an ensemble of specialized models
from nearby clusters for inference. Simultaneously, SPECIALIZER
records the input to train a specialized model.